
티스토리 뷰
Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
구글이 음성 번역기와 관련된 내용을 발표하였네요.
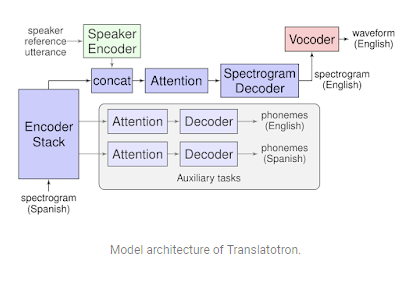
아래 구조도 그림과 같이 Spanish 음성이 입력되면 Spanish 를 Decoder가 Text화하여 English 로 번역을 하고, Spanish 발음 자체를 Encoding 하여 번역된 Text를 Spectrogram Decoder 가 English로 번역된 Spectrogram을 Vocoder에 전달하여 최종적으로 사람이 들을수 있는 Waveform 으로 번역하여 출력해주는 순서입니다.
이러한 기술이 상용화되면 영상의 더빙과 같이 성우들이 별도로 음성 녹음을 하지 않더라도 기존 성우의 말투나 억양과 유사한 톤으로 번역된 음성을 들을수 있게 될 것 같습니다.
각 나라별 언어의 억양과 톤을 상호 교차 적용하는데에는 무척 많은 음성 데이터들이 필요할것 같고 매우 복잡한 연산 방식이 들어갈것같네요. 상용화가 무척 기대됩니다.
자세한 링크는 아래 참조하세요
https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html
Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
Posted by Ye Jia and Ron Weiss, Software Engineers, Google AI Speech-to-speech translation systems have been developed over the past sever...
ai.googleblog.com
'Life > IT' 카테고리의 다른 글
| 배터리 단위 mAh 와 Wh 의 차이 비교 (0) | 2020.01.29 |
|---|---|
| GPS 좌표의 위도,경도 좌표값 도분초 변환 (도°분'초") (1) | 2019.09.23 |
| SAMSUNG Galaxy Fold 갤럭시폴드 (0) | 2019.02.21 |
| 기계식 키보드 스위치 종류 (0) | 2018.03.26 |
| Gear S3 Design (0) | 2017.05.29 |